
Episode 37
AI is Your Heart’s Friend

Educators in Medicine,
In this newsletter, we continue our journey through the fundamentals of AI, its applications in medicine, and its transformative role in faculty development and education. Let’s dive into learning.
1: From Congestive to Cognitive: AI and Heart Failure
Let’s start with our hearts. Heart failure (HF) affects nearly 6.7 million Americans today and is projected to hit 8.5 million by 2030. Despite advancements in guideline-directed medical therapy, heart failure outcomes remain grim for many. Enter AI.
A recent paper from J Card Fail (Goyal et al., 2025) walks through how artificial intelligence is now helping clinicians optimize care in heart failure management. We’re talking early detection, tailored risk stratification, and predictive analytics that are actually useful at the bedside—not just buzzwords at a tech conference.
Thanks to Dr Prida- our Cards fellowship PD - who shared this article with me at our Program Director Workshop (naturally…on AI in GME)
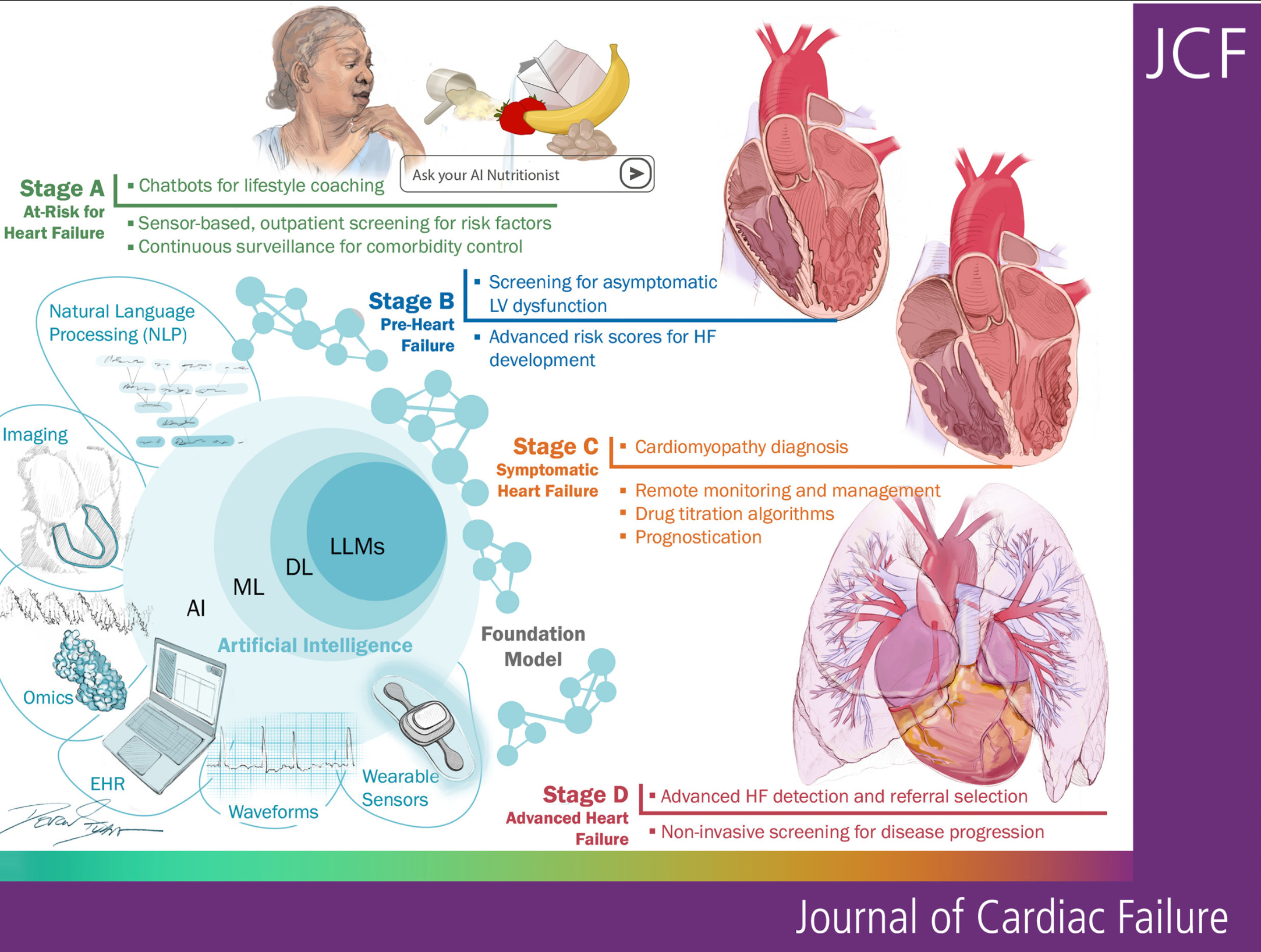
For example, AI models can detect subtle trends from patient-reported symptoms and wearables like smartwatches (yes, your Apple Watch may actually care more about your heart than you ever did). It flags fluid retention before weight gain and wheezing shows up on the scale or auscultation and when BNP levels haven’t budged.
🩺 Clinical teaching idea: Let’s work with learners to review this paper and point out AI-tools to support predictions alongside classic metrics like NYHA class. Ask them: Would this change your management? Why or why not?
I will say - we have to get patients the wearables to see these detailed data. Scalable implications are coming - and for now cell phone interaction with LLMs for self reporting is definitely a possibility. Think RPM via LLM chats.
2: Rethinking How We Learn from Trials
Now let’s talk trials—RCTs, to be exact. But clinical trial participants often look nothing like the real patients we see. They’re younger, less comorbid, and oddly cooperative. It’s like trying to learn about marriage from a rom-com.
That’s where phenomapping enters. A clever study in Circulation: Cardiovascular Outcomes (Choudhry et al., 2024) used computational phenomapping to compare trial participants to real-world EHR populations. By aligning phenotypes—think age, race, comorbidities—they could determine how representative the trial cohort really was.
Even better? This approach allows us to recalculate treatment effects for different subpopulations. Now, students and residents don’t just memorize trial inclusion/exclusion criteria—they can question the external validity in their clinic’s context.
“This is a single-site study, at an urban academic medical center”
“Not generalizable”
I think this conversation will happen less often with these breakdown/apply to our practice settings.
As a random aside, I’ve posed the idea of re-running the stats of guideline-making papers. I wonder if AI tools could help us code the python/R needed to re-evaluate the inputs from the systematic review, and decide if the guidelines are pieced together appropriately? I assume that if we checked 3 or so, we’d find no error. But I wonder if publication bias has a role in these? what if we did 300 reviews? I wonder how many we’d find conclusions were inaccurate?
That could be an interesting study.
3. Critical Appraisal: Don’t Just Believe the Hype
At times, I have been a part of the AI hype train moving through your inboxes, journals, and conferences. Some days I am more based and even apprehensive. But how do we know if that shiny AI tool actually works in practice?
The BMJ Medicine article, "How to Read a Paper Involving AI", is your new must-read. It walks us through how to critically appraise AI research, breaking down AI model development, bias, data transparency, and real-world applicability.
They had a great 10 question tool to assess AI tools. Some are more subjective, but I did enjoy the framework.
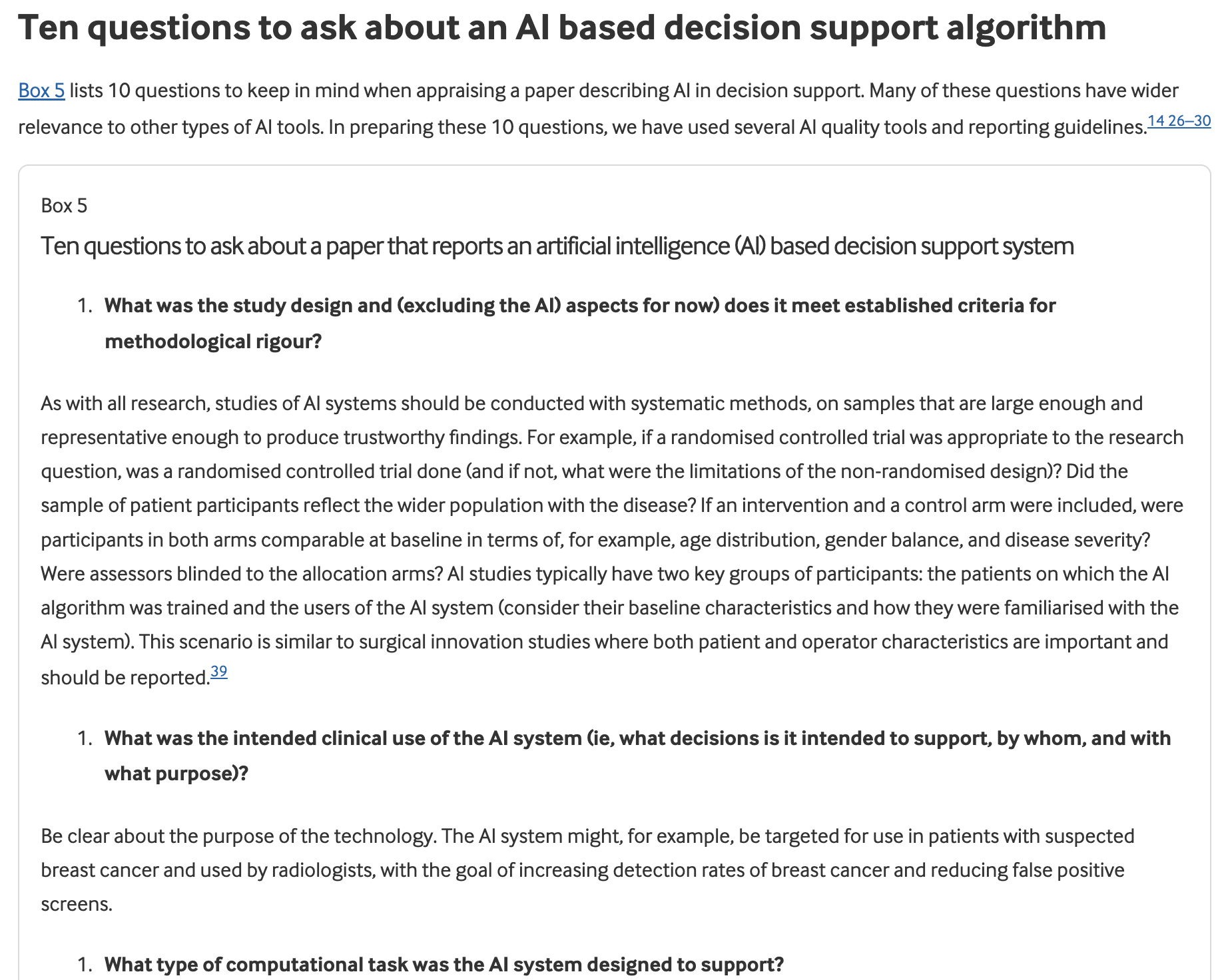
More importantly, this paper gives educators and clinicians a vocabulary to talk back to AI. Not everything that glitters is clinical gold.
At the AI Teaching Hospital, we gave our clerkship students a paper describing a machine learning tool predicting hospital readmissions. Then I asked them: “What’s missing from this study?” The conversation does not naturally go to datasets, model retraining needs, and ethical concerns. I hope this can help us as educators be more equipped.
📚 Teaching idea: Have residents apply the BMJ AI appraisal framework to a new AI diagnostic paper/tool.
As always - get in touch and let me know your thoughts!
Thank you for joining us on this adventure. Stay tuned for more AI insights, best practices, and more future editions of AI+MedEd.
For education and innovation,
Karim
Share this with someone - have them sign up here.